AlexNet
Training AlexNet from Scratch
AlexNet is a landmark convolutional neural network (CNN) architecture proposed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton. The model is famous for its performance in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012, achieving a significant improvement over the previous state-of-the-art.
Since there exist already a myriad of resources that cover the details of AlexNet, I’d like to simply use this post to summarize my experience with training it on Tiny ImageNet.
My implementation can be found here.
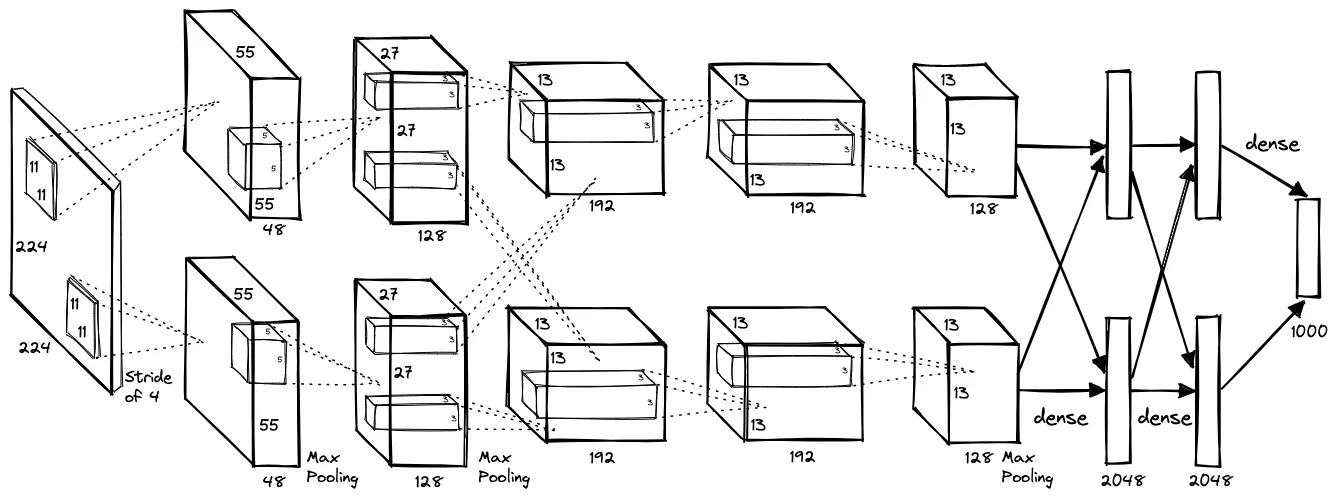
Network Architecture
The network consists of 8 total layers: 5 convolutional layers and 3 fully connected layers. The output of the final fully connected layer is fed to a 1000-way softmax layer for classification on the original ImageNet dataset. In our implementation, the final layer is replaced with a 200-way softmax layer for the Tiny ImageNet dataset.
A basic summary of layers
- ReLU Non-linearity: allows for faster training than sigmoid and tanh.
- Local Response Normalization (LRN): normalizes the output of a neuron in a local region to help improve generalization. This normalization is applied after ReLU in specific layers.
- Max Pooling: downsamples the output of the convolutional layers.
- Dropout: helps to prevent overfitting.
Training + Optimizer
- Multinomial Logistic Regression Objective (Cross-Entropy Loss)
- Stochastic Gradient Descent (SGD) optimizer with momentum of \(0.9\), weight decay of \(0.0005\), and learning rate of \(0.01\).
Implementations in original paper that we do not use:
- Training with \(90\) epochs and a batch size of \(128\).
- A key innovation was parallelizing the training across 2 GPUs for 5-6 days which we do not need.
Instead we do:
- Training with ~\(30\) epochs and a batch size of \(128\).
- Training on a single GPU (colab T4 GPU is sufficient)
Results
The final results after training for ~\(30\) epochs are as follows:
Test Top-1 accuracy: 31.754350662231445 % | Top-5 accuracy: 58.7618670886076 %
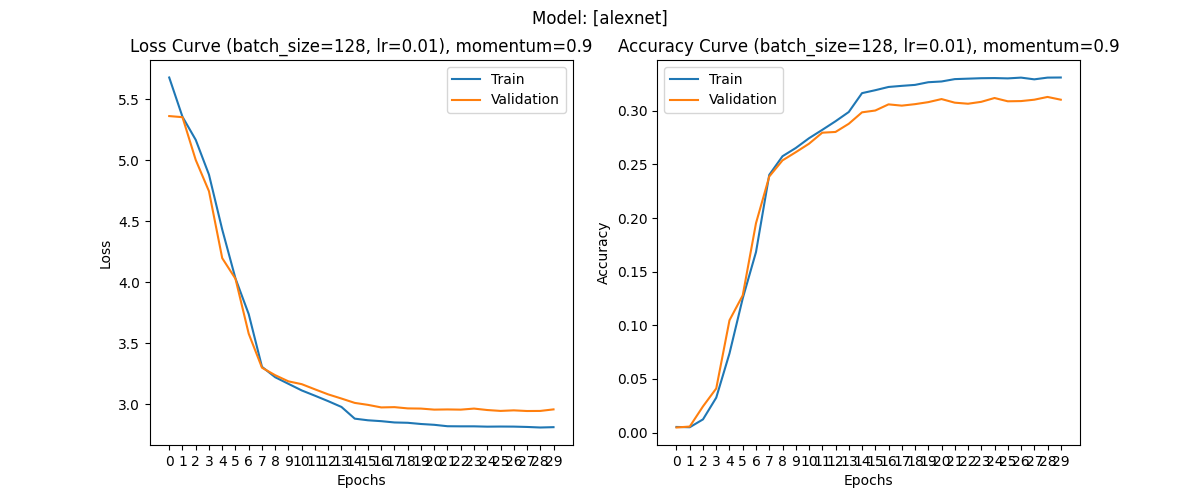
Considering that the paper reports top-1 and top-5 error rate scores of \(67.4\%\) and \(40.9\%\) on ImageNet, we can say that the implementation is sufficiently accurate for the Tiny ImageNet dataset.
Top-1 and top-5 accuracies are inversely equivalent being \(32.6\%\) and \(59.1\%\) respectively.
Some Insights on My Implementation Journey
1. Different PyTorch implementation
Apparently, the implementation of the current PyTorch AlexNet model is different than the original paper. This github issue goes into some detail about it: pytorch/vision/issues/549
Overall, both implementations are similar.
2. Using Top-K metrics to evaluate performance
While accuracy (otherwise referred to as Top-1 accuracy) is a common metric for evaluating the performance of a model, it can be misleading in some cases.
For example, for a large number of classes like in Tiny ImageNet (200 classes), the complexity of our classification task increases and in early stages of training, a simple accuracy metric may be extremely low and misleading. A Top-5 accuracy metric, which measures the percentage of times the correct class exists in the top 5 predictions, is a much more forgiving and informative metric.
3. Make sure that data preprocessing is done correctly
Sometimes a simple mistake is all you need to ruin your day.
4. Find a suitable batch size
It goes without saying that hyperparameter tuning is a crucial part of training deep learning models. Aside from the conventional knowledge of higher batch sizes = higher memory usage, too large a batch size can also cause overfitting. Too small and training is inefficient.
A balance is needed and in our case, \(128\) worked out.